MAEZ insight
Understanding Common Issues in Chain of Responsibility
A practical guide to common pitfalls when implementing the Chain of Responsibility design pattern, including misapplication, performance overhead, debugging challenges, concurrency concerns, and how to choose the right pattern.

Proof that freight promises do not create unsafe transport pressure.

Loading controls need evidence, not assumptions.
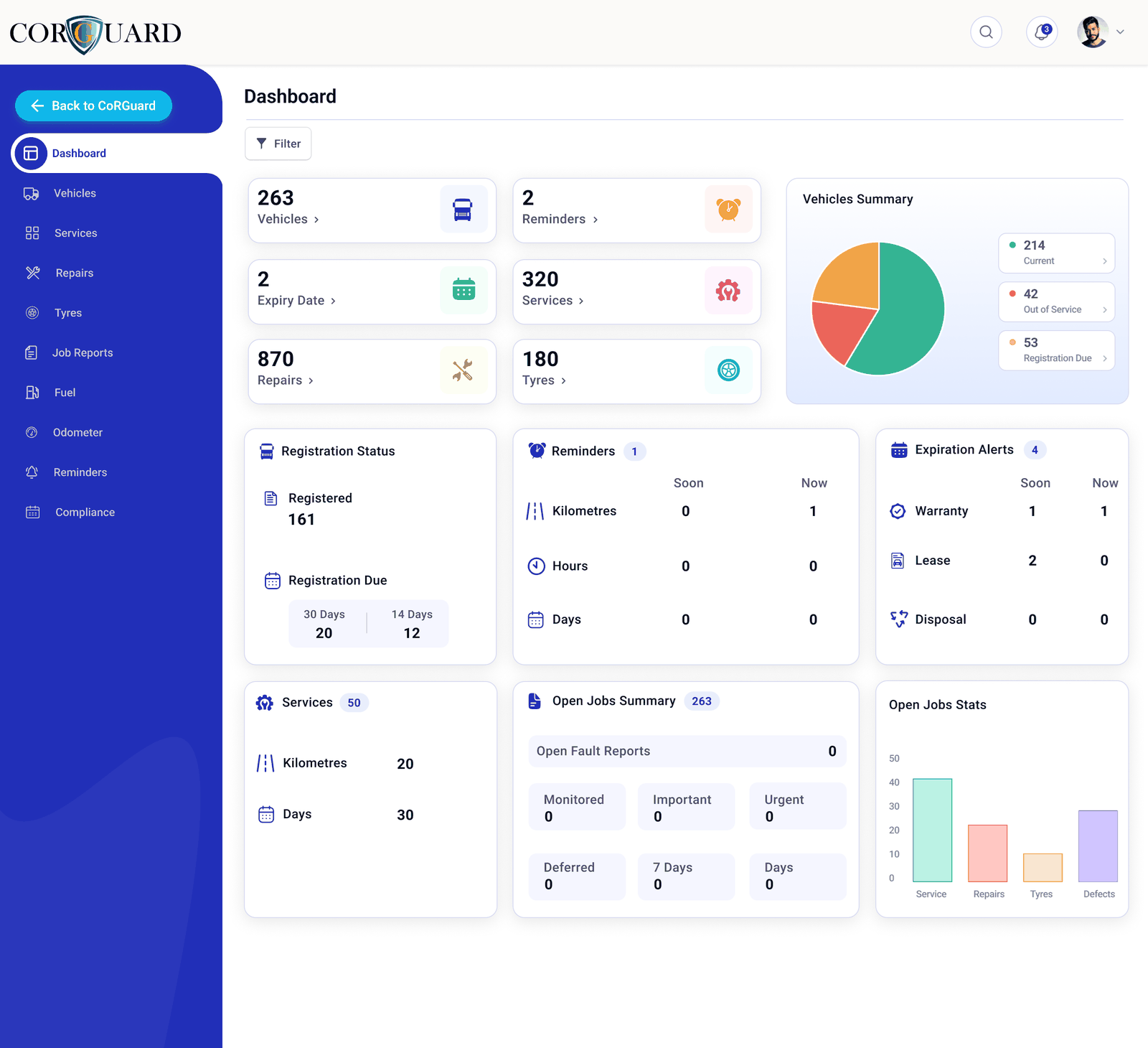
Daily fleet activity has to connect back to duties, controls, and review.

Due diligence means knowing whether the safety system is actually working.
Consignors
Role-based Chain of Responsibility controls, evidence, and SMS expectations.
Consignees
Role-based Chain of Responsibility controls, evidence, and SMS expectations.
Loaders
Role-based Chain of Responsibility controls, evidence, and SMS expectations.
Managers
Role-based Chain of Responsibility controls, evidence, and SMS expectations.
What Is the Chain of Responsibility Pattern?
A behavioural pattern for decoupling request senders from receivers

The Chain of Responsibility is a behavioural design pattern that passes requests along a chain of handlers, where each handler either processes the request or forwards it to the next. Common issues include misapplying the pattern to non-linear business logic, performance overhead from deep handler chains, silent unhandled request failures, debugging complexity from implicit execution paths, and thread safety risks with shared mutable state.
The pattern is classified as a behavioural design pattern in the GoF (Gang of Four) catalogue. This classification matters because it defines how objects interact and distribute responsibilities. The pattern works through a simple mechanism: a request passes along a chain of handlers where each handler can either process the request or forward it to the next handler.
This creates an important benefit — the pattern decouples request senders from specific receivers. The sender only knows that a request enters a chain, not which concrete handler will deal with it. Decoupling senders from receivers enables flexible, evolvable pipelines without client-to-handler coupling.
The pattern works well for specific scenarios such as authentication pipelines, logging systems, and middleware stacks. But force it into the wrong situation and you'll spend weeks untangling the mess.
How the Pattern Actually Works
Handler chains, decision logic, and the three core components

Each handler in the chain holds a reference to the next handler. When a request arrives, the handler decides whether to process it or pass it forward. This decision logic varies based on your requirements. Authentication systems demonstrate this well — a request might flow through these handlers:
- Token validation handler checks for valid authentication tokens
- Authorization handler verifies user permissions
- Rate limiting handler ensures request frequency stays within bounds
- Business logic handler processes the actual request
Each handler focuses on one responsibility, making the system easier to maintain and extend.
The Three Core Components
Three elements form the pattern's foundation:
- Handler interface — defines the contract all handlers must follow
- Concrete handlers — implement specific processing logic
- Client — initiates requests without knowing which handler will respond
This structure supports the Open/Closed Principle: you can add new handlers without modifying existing code. The chain grows organically as requirements evolve. Understanding this foundation helps you recognise when problems arise — most issues stem from violating these core principles.
When Does the Pattern Become a Problem?
Recognising warning signs before you overbuild

Developers often reach for Chain of Responsibility because it sounds elegant. Sequential processing through a chain feels intuitive. But this intuition misleads when the problem doesn't match the pattern's strengths. A Strategy pattern or simple conditional dispatch can be clearer and more efficient than building a full Chain of Responsibility pipeline.
Linear Chains for Complex Business Logic
Business processes rarely follow strict linear paths. They branch based on conditions, run steps in parallel, or require backtracking. Forcing these into a chain creates artificial constraints. Complex business processes with conditional or parallel steps are better represented as state machines or workflow engines.
Consider an order processing system where you might need to:
- Validate payment and check inventory simultaneously
- Route to different fulfilment handlers based on product type
- Retry failed steps without reprocessing successful ones
- Cancel the entire order if any critical step fails
A linear chain struggles with these requirements. You end up adding complex routing logic to individual handlers, defeating the pattern's purpose.
Performance Overhead Accumulation
Adding more layers in middleware pipelines and layered architectures increases latency and processing overhead. Each handler adds method calls, conditional checks, and potential state management. This overhead compounds quickly. A chain with ten handlers might add milliseconds to each request — under high load, those milliseconds become seconds of total processing time.
The problem intensifies when handlers perform expensive operations such as database queries, external API calls, or complex calculations in every handler. The chain becomes the slowest common denominator.
Choosing the Right Pattern
Avoiding confusion between Chain of Responsibility, Decorator, and Strategy

Confusing intents — using Chain of Responsibility instead of Decorator or simple composition — leads developers to misapply the pattern. This confusion creates awkward designs that fight against natural code structure.
Each behavioural pattern serves specific purposes. Chain of Responsibility handles requests through sequential decision points. Decorator adds responsibilities to objects dynamically. Strategy selects algorithms at runtime. Developers mix up these patterns because they share surface similarities, but their internal mechanics differ significantly.
When Chain of Responsibility Fits vs. Alternatives
- Multiple handlers might process the same request — Chain of Responsibility is a perfect fit
- Enhance an object with additional features — use the Decorator pattern instead
- Select one algorithm from many options — use the Strategy pattern instead
- Unknown handler at compile time — Chain of Responsibility is a core strength
- Wrap functionality around a core object — use Decorator or Proxy instead
The pattern shines when you need dynamic handler chains. When handlers are fixed and known, simpler approaches work better.
Overengineering Simple Problems
Not every sequential operation needs the full Chain of Responsibility treatment. Sometimes a simple if-else chain or switch statement does the job perfectly. Before implementing the pattern, ask yourself:
- Will I add or remove handlers at runtime?
- Do different clients need different handler chains?
- Must handlers remain unaware of each other?
- Will the chain grow beyond three or four handlers?
If you answered no to most of these questions, you probably don't need Chain of Responsibility. The complexity it adds won't pay off.
Solving the Unhandled Request Problem
Preventing silent failures with safety nets and explicit contracts

Every chain must answer one critical question: what happens when no handler processes the request? This scenario occurs more often than developers expect. A request might fall through the entire chain because:
- No handler's conditions match the request type
- Each handler assumes another will handle it
- The chain configuration contains gaps in coverage
- The request format changed but handlers weren't updated
Silent failures cause the worst problems. The request disappears without errors or logs. Users experience mysterious failures that leave no debugging trail.
Implementing Safety Nets
Smart implementations add a default handler at the chain's end. This handler catches all unprocessed requests and takes appropriate action. Your default handler should:
- Log the unhandled request with full context
- Return a clear error message to the caller
- Track unhandled request metrics for monitoring
- Provide fallback behaviour when appropriate
This pattern appears in mature systems like web frameworks, where the final handler returns a 404 error instead of silently dropping requests.
Explicit Handling Contracts
Each handler should explicitly indicate whether it handled the request. Boolean return values work well for this purpose — the chain knows exactly when to stop processing, and handlers can't accidentally pass through requests they should have handled. Document this contract clearly in your handler interface to make it impossible for implementers to create handlers that violate the pattern.
Debugging and Maintenance Challenges
Gaining visibility into chain execution and managing configuration

Chain of Responsibility creates unique debugging challenges. The request path through the system becomes implicit rather than explicit. Tracing execution requires following references through multiple objects, and traditional debuggers struggle — setting breakpoints in each handler becomes tedious.
Visibility Into Chain Execution
Production issues with chains feel like detective work. Something went wrong, but where? Which handler failed? Did the request reach all expected handlers? Implement structured logging at each handler. Log these details:
- Handler name or type entering processing
- Request identifier for correlation
- Processing decision: handled, passed, or rejected
- Execution time within this handler
- Any errors or warnings encountered
This logging creates an audit trail. You can reconstruct the exact path any request took through the chain.
Configuration Management Complexity
Chains configured at runtime create deployment risks. The configuration determines system behaviour, but it lives outside the code and version control doesn't track it naturally. Teams face these challenges:
- Configuration changes between environments cause inconsistent behaviour
- No clear owner for chain configuration decisions
- Testing all possible chain configurations becomes impractical
- Rolling back bad configurations requires coordination
Treat chain configurations as critical infrastructure. Version them, review them, and test them thoroughly before deployment.
Concurrency and Thread Safety Issues
Managing shared state when handlers process concurrent requests
Middleware pipelines that modify a shared request or context object must ensure thread safety when handling concurrent requests. This requirement complicates implementations significantly. Shared mutable state creates race conditions — multiple threads might process different requests through the same chain simultaneously. Handlers that modify shared objects cause data corruption.
State Management Strategies
Three approaches handle concurrency safely:
- Immutable request objects — prevent modification races by having each handler return a new request instance rather than mutating the original
- Thread-local context — give each request its own isolated context so handlers never share mutable state across threads
- Synchronised access — use locks or concurrent data structures when immutability isn't practical, accepting the performance trade-off
Immutable request objects are the preferred approach where feasible. They eliminate an entire class of concurrency bugs without adding locking overhead. When that's not practical, thread-local context provides isolation without global synchronisation costs.
For broader guidance on managing responsibility across complex systems and teams, see our Chain of Responsibility consulting services or explore CoR training options for your team.
Operational message set
Find the gaps. Fix the system. Prove the controls.
MAEZ helps transport operators deal with the compliance risk they already know is there. We help get the Safety Management System in order, protect NHVAS accreditation, reduce fine exposure, and connect training, evidence, and CoRGuard workflows where software is needed.
Find
Identify what is exposed before an auditor or regulator does.
Fix
Build the SMS controls around how the transport business actually runs.
Prove
Use CoRGuard where records, reminders, diaries, audits, and evidence need structure.
Evidence path
From MAEZ advice to a working Safety Management System
Advisory work should leave a practical implementation trail. These examples show how CoRGuard supports records, fatigue and driver diary checks, maintenance, audits, document control, inductions, corrective actions, and evidence review after MAEZ identifies the gaps.
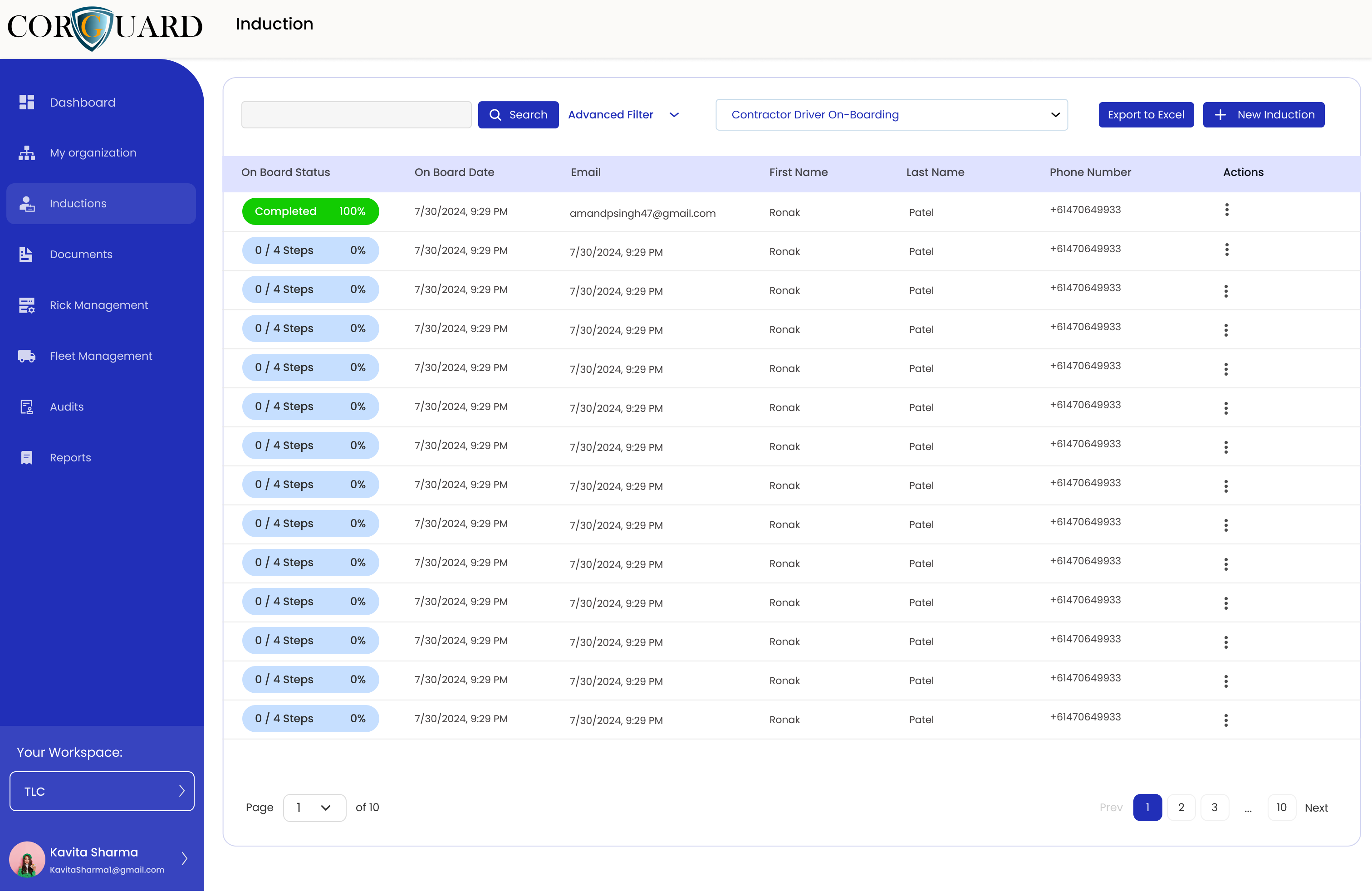
Training records
Connect training completion from cortraining.com.au to evidence and follow-up.
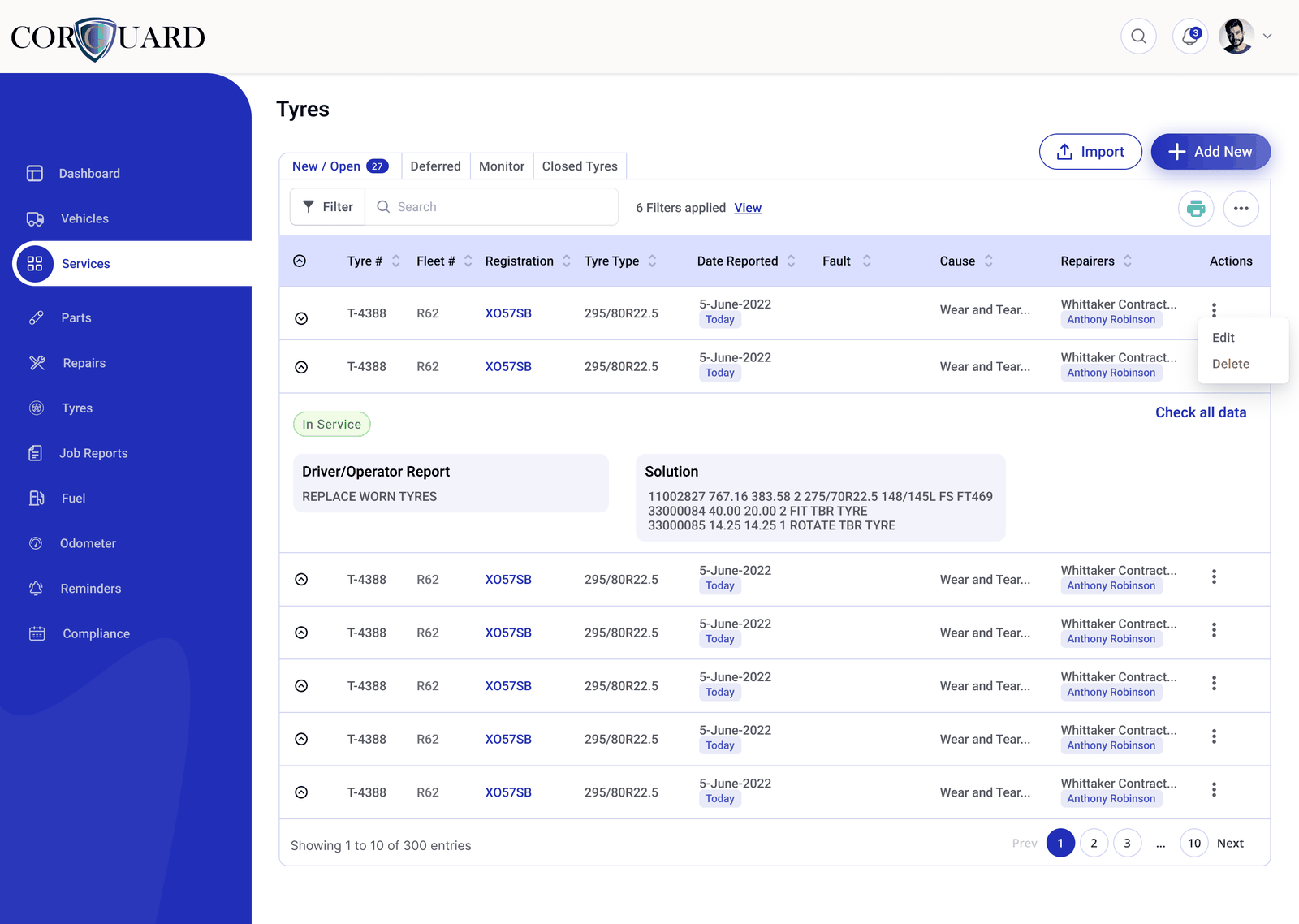
Driver diary checks
Connect fatigue and driver diary review back to manager visibility.
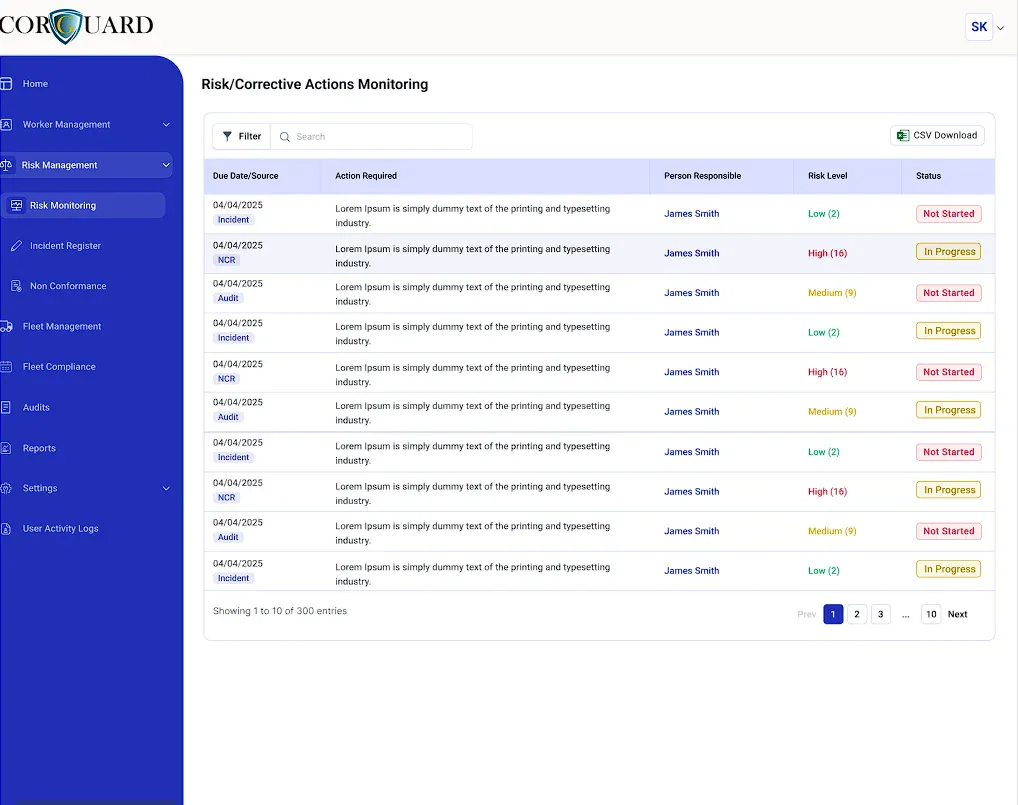
Corrective actions
Turn audit findings, hazards and incidents into tracked actions.
Keep exploring
Related Chain of Responsibility reading
MAEZ insight
Enhancing Transport Safety: Effective Strategies and Tips
Discover how to improve transport safety with effective strategies. Learn to integrate safety culture and technology for better performance.
MAEZ insight
Understanding Common Transport Safety Issues: A Guide
Explore common transport safety issues affecting global operations. Learn preventive measures to protect lives and improve safety standards.
MAEZ insight
Effective Strategies for Managing Global Supply Chain Risks
Discover effective global supply chain risk management strategies to mitigate operational challenges and enhance supply chain resilience.
MAEZ insight
Essential Chain of Responsibility Compliance Tips Explained
Discover essential chain of responsibility compliance tips to ensure safety and meet HVNL obligations. Stay informed and compliant with our expert advice.
MAEZ insight
Exploring Effective Safety Management System Examples
Discover effective Safety Management System examples to enhance workplace safety through structured frameworks and core components.
MAEZ insight
Understanding Key Components of a Safety Management System
Discover the crucial components of a safety management system, including Safety Policy and Risk Management, to enhance organizational safety outcomes.
Frequently asked questions
Questions people ask about this topic
What is the Chain of Responsibility design pattern?
The Chain of Responsibility is a behavioural design pattern that passes requests along a chain of handlers, where each handler either processes the request or forwards it to the next handler. It decouples the sender from the receiver, so the sender doesn't need to know which handler will ultimately handle the request.
When should I avoid using the Chain of Responsibility pattern?
Avoid Chain of Responsibility when business logic involves branching, parallel steps, or backtracking rather than strict sequential processing. Also avoid it when handlers are fixed and known at compile time, or when a simple if-else chain or switch statement would achieve the same result with less complexity.
How do I prevent silent failures in a Chain of Responsibility pipeline?
Add a default handler at the end of the chain that catches all unprocessed requests, logs the full context, returns a clear error to the caller, and tracks metrics. Each handler should also use a boolean return value to explicitly indicate whether it handled the request, preventing accidental pass-through.
What are the main concurrency risks with the Chain of Responsibility pattern?
When multiple threads process requests through the same chain simultaneously, shared mutable state in request or context objects can cause race conditions and data corruption. The safest approach is using immutable request objects so each handler returns a new instance rather than mutating the original.
How is Chain of Responsibility different from the Decorator or Strategy pattern?
Chain of Responsibility passes requests through sequential decision points where any handler may process or forward the request. Decorator dynamically adds responsibilities to an object by wrapping it. Strategy selects one algorithm from many at runtime. Each pattern shares surface similarities but serves a distinct purpose.